Outils du BIN
3. git – les bonnes pratiques
Dans ce guide, nous répondrons à la question de savoir quelles sont les meilleures pratiques à respecter lorsqu'on utilise l’outil de contrôle de version git. Ce guide prend pour acquis que vous connaissez les bases de git. Si ce n'est pas le cas, nous vous invitons à vous familiariser avec les commandes de bases de git avant de consulter ce guide.
Le site web w3school offre un tutoriel assez complet disponible ici.
Pourquoi dit-on que git est un outil de «contrôle de versions»? Parce que dans le développement de logiciels, git permet de sauvegarder différentes versions du même logiciel afin de pouvoir les redéployer au besoin.
Dans le cadre de projet en sciences des données cependant, git sert d'abord et avant tout à deux choses :
- Sauvegarder l'évolution du projet afin de permettre le retour en arrière.
- Travailler en équipe sur le même projet.
Dans ce guide, nous allons nous intéresser :
- au fichier
.gitignore; - à la fréquence à laquelle
pull,commitetpush; - aux messages des commits;
- aux branches (pourquoi en faire, et quand les merge);
Le fichier .gitignore
On veut généralement que notre répertoire git soit léger en termes de mémoire. Pour ce faire, il est conseiller de seulement suivre les fichiers qui contiennent le code. Étant donné que le répertoire qui contient notre projet sur notre ordinateur contient généralement aussi autre chose que le code (les données par exemple), il est nécessaire de dire à git d'ignorer certains répertoires et certains types de fichiers. C'est ce à quoi sert le fichier .gitignore. Ce fichier doit être placé à la racine du projet pour que git le détecte.
On conseiller de mettre les fichiers et les répertoires suivants dans le fichier .gitignore :
- le code compilé (exécutables) – ex : fichiers en .o, .pyc, et .class;
- les fichiers binaires et les images – ex : .jpeg, .db;
- les caches des dépendances – ex : le contenu de /node_modules ou /packages;
- les répertoires des fichiers exécutables – ex : /bin, /out, ou /target;
- les fichiers logs ou temporaires – ex: .log, .lock, ou .tmp;
- les fichiers systèmes cachés – ex : .DS_Store or Thumbs.db;
- les fichiers configs d'environnements : – ex : idea/workspace.xml;
- les répertoires de données : – ex : /data
- les données : – ex : les fichiers .csv
Voici un exemple de fichier .gitignore :

La fréquence à laquelle pull commit et push
Un des objectifs de cette section est de proposer une méthode de travail qui permet le plus possible d'éviter d'avoir à gérer de gros conflits. Vous le savez sans doute si vous lisez ce guide, lorsqu'on travaille avec git en équipe sur un même projet, il est presque impossible qu'on n’ait jamais à gérer des conflits. Un conflit a lieu lorsque deux coéquipiers ont modifié le même fichier de code. Il est relativement aisé de gérer un conflit sur un fichier de code. Mais lorsque plusieurs fichiers ont plusieurs conflits, et que certains fichiers sont interdépendants les uns avec les autres, cela peut rapidement devenir un cauchemar. Pour éviter cela, c'est assez simple, il faut pull commit et push souvent.
Le pull
Lorsqu'on travaille en équipe, il est généralement recommandé de faire un pull chaque fois qu'on commence une journée de travail sur un projet. On s'assure ainsi de commencer à travailler sur un projet à jour. Modifier un fichier qui n'est pas à jour avec notre répertoire distant est la recette parfaite pour créer des conflits.
Le commit et le push
Il est recommandé de faire des commits relativement souvent (quelques fois par journée de travail) et de push à chaque fois. Faire des commits à court interval permet de retourner en arrière de manière plus précise, sans risquer de perdre plusieurs heures de travail. Cela permet aussi à l'équipe de retracer quand a été fait chaque changement (si les commits sont bien nommés). Cela rend aussi la gestion des conflits plus facile. Si tous les membres de l'équipe font des commits et des pushs fréquents, on sera plus en mesure de détecter rapidement lorsqu'il y a conflit. Les conflits seront moins difficiles à gérer.
La règle générale que vous devriez suivre pourrait être énoncée de la manière suivante : faites un commit chaque fois que vous avez complété une tâche. Évitez de faire des commits où plusieurs tâches ont été faites. La question se pose de savoir ce que représente «une tâche». Il est difficile de tracer la frontière de ce que représente «une tâche», mais on peut penser à :
- écrire une fonction;
- corriger un bug;
- documenter une fonction;
- réusiner un script particulier;
- etc.
Une tâche doit pouvoir être décrite par un message simple. Ces considérations nous renvoient à la prochaine section, mais nous croyons que le fait de commit après la complétion d'une tâche, rendra le travail de rédaction des messages associés aux commits beaucoup plus simple.
Les messages des commits
Vous avez probablement été déjà confronté à une panne d'inspiration
lorsqu'est venu le temps d'écrire le message descriptif d'un de vos
commits. Ce mème exprime, possiblement, assez
bien ce à quoi ont déjà ressemblé vos messages de commits (l'auteur de ces
lignes s'avoue coupable) :

source : https://xkcd.com/1296/
Si se conformer aux bonnes pratiques exige que l'on fasse souvent des
commits, cela exige aussi que l'on écrive des messages descriptifs
informatifs pour chacun de ces commits. Comme on l'a vu dans le précédente
section, le fait d'être en mesure d'écrire de courts messages informatifs
est étroitement lié au contenu de notre commit. Il sera difficile de décrire
en quelques mots ce qu'on a fait pendant des journées entières de travail.
Il sera, au contraire, assez aisé de décrire en quelques mots une modification
qu'on a apportée à une fonction particulière qui nous a pris moins d'une heure
de travail.
Si la fréquence à laquelle on commit est motivée par le désir d'écrire
des messages informatifs, la tâche deviendra automatiquement plus simple.
L'auteur de ce billet de blog propose de précéder chaque message d'une étiquette nous informant du type de modification qui a été fait par le commit, ce que nous semble une excellente idée :
- [fonc] pour l’ajout d’une fonctionnalité;
- [modif] pour la modification d’une fonctionnalité;
- [supp] pour la suppression d’une fonctionnalité ou fichier;
- [corr] pour la correction d’un bug;
- [reus] pour le réunisage ( refactor ) du code;
- [autr] quand aucun des tags précédents ne correspond à la tâche;
Gestion de branches
Dans un petit projet, il est souvent non-nécessaire de faire des branches.
Ce qu'il faut savoir c'est que créer une branche génère un danger, et on l'évite en s'abstenant de faire des branches. Le danger est le suivant :
Le merge conflict.
Plus longtemps deux personnes travaillent sur deux branches
différentes, plus la différence entre les deux versions du projet augmente,
et plus la possibilité de devoir gérer un énorme conflit augmente. Cela
peut faire en sorte qu'on se retrouve avec deux versions parallèles de
notre projet qui sont tellement difficiles à merge qu'on abandonnera tout simplement
le projet de le faire. On veut éviter cela à tout prix
Quoi faire en cas de merge conflict?
Pas de panique! Résoudre un conflit signifie simplement qu’on devra sélectionner ce qu’on veut conserver dans les deux versions des fichiers en conflit. Vous pouvez faire cela à la main (modifier directement le fichier dans lequel il y a un conflit). Nous vous conseillons ce guide pour en savoir plus. Il existe sinon plusieurs outils avec des interfaces graphiques qui permettent de gérer les conflits de manière plus conviviale. On pense, par exemple, à Sourcetree mais aussi à certains environnements de développement ou des éditeurs de code qui offrent ce service comme Pycharm ou VScode.Pourquoi faire une branche?
Pourquoi faire une branche si cette pratique semble dangereuse?
Faire une branche est nécessaire lorsqu'on veut faire des modifications au code qui risque de briser des parties du code avec lesquelles d'autres membres de l'équipe doivent travailler.
Si notre code n'est pas susceptible de briser quoi que ce soit pour les autres, il n'est pas nécessaire de faire une branche.
La méthode gitflow
La motivation
La méthode gitflow est très utilisée dans le monde du développement de logiciels. Nous ne croyons pas qu'elle soit nécessaire pour la majorité des projets en sciences des données. Cette méthode vise essentiellement deux choses :
- Permettre à plusieurs personnes de travailler en parallèle sur le développement de différentes fonctionnalités d'un logiciel sans nuire au travail des autres.
- Garder distinctes une version stable du projet (qui peut être utilisée par les utilisateurs du logiciel) et une version en développement, qu'on peut se permettre de briser, et sur laquelle on teste les nouvelles fonctionnalités.
Nous vous laissons répondre à la question de savoir si votre projet est suffisamment complexe pour bénéficier de cette méthode.
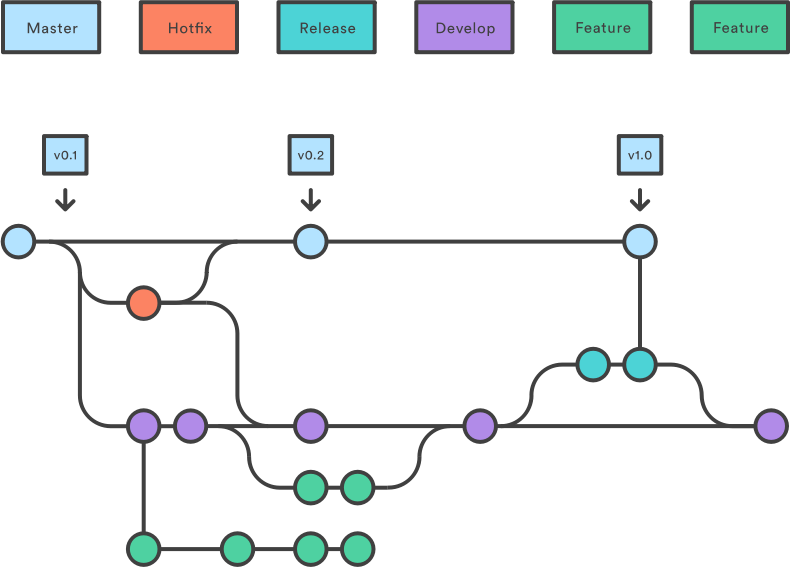
La méthode
Dans la méthode gitflow on utilise 4 types de branche.
- Master : qui contient la version stable du projet.
- Development : qui est la branche sur laquelle les modifications sont faites pendant la phase active de développement du logiciel.
- Features : qui sont toutes les branches qui sont créées pour développer une nouvelle fonctionnalité (une branche par fonctionnalité).
- Release : qui sont des branches qu'on crée uniquement afin de
mergeles changements de la branche Development dans la branche Master (pour ne pas directementmergeDevelopment dans Master).
Le développement de nouvelles fonctionnalités se fait de la manière suivante :
- Lorsqu'une personne veut ajouter une nouvelle fonctionnalité, elle crée une nouvelle branche au nom de la fonctionnalité qu'elle veut développer à partir de la branche Development
- Lorsque la fonctionnalité est prête, elle merge sa branche dans la branche Development.
- Des tests sont faits pour s'assurer que la nouvelle fonctionnalité (ou l'interaction des nouvelles fonctionnalités) n'a pas brisé le logiciel.
- Lorsque le logiciel est stable dans la branche Developement, et est prêt à être déployé, on crée une branche Release à partir de la branche Development.
- On merge la branche Release dans Master.
Pour une explication plus détaillée (en anglais) de la méthode gitflow, voir ce guide
Tutoriels
https://webpick.info/les-bonnes-pratiques-de-git-pour-un-developpeur/
https://medium.com/@pilloud.anthony/git-les-bonnes-pratiques-b0f19c3eef47